May -Akda:
Charles Brown
Petsa Ng Paglikha:
9 Pebrero 2021
I -Update Ang Petsa:
1 Hulyo 2024

Nilalaman
- Upang humakbang
- Paraan 1 ng 3: Kalkulahin ang SSE sa pamamagitan ng kamay
- Paraan 3 ng 3: Iugnay ang SSE sa iba pang mga istatistika
Ang kabuuan ng mga parisukat, o SSE, ay isang paunang pagkalkula ng istatistika na humantong sa iba't ibang mga halaga ng data. Kapag mayroon kang isang hanay ng mga halaga ng data, kapaki-pakinabang upang matukoy kung gaano kalapit ang kaugnayan sa mga halagang ito. Kailangan mong ayusin ang iyong data sa isang talahanayan at pagkatapos ay magsagawa ng medyo simpleng mga kalkulasyon. Kapag nahanap mo ang SSE para sa isang hanay ng data, maaari mo nang makita ang pagkakaiba-iba at karaniwang paglihis.
Upang humakbang
Paraan 1 ng 3: Kalkulahin ang SSE sa pamamagitan ng kamay
 Lumikha ng isang talahanayan ng tatlong haligi. Ang pinakamalinaw na paraan upang makalkula ang SSE ay magsimula sa isang talahanayan ng tatlong haligi. Lagyan ng label ang tatlong haligi
Lumikha ng isang talahanayan ng tatlong haligi. Ang pinakamalinaw na paraan upang makalkula ang SSE ay magsimula sa isang talahanayan ng tatlong haligi. Lagyan ng label ang tatlong haligi  Punan ang mga detalye. Naglalaman ang unang haligi ng mga halaga ng iyong mga sukat. Punan ang haligi
Punan ang mga detalye. Naglalaman ang unang haligi ng mga halaga ng iyong mga sukat. Punan ang haligi  Kalkulahin ang ibig sabihin. Bago mo makalkula ang error para sa bawat pagsukat, dapat mong kalkulahin ang ibig sabihin ng buong hanay ng data.
Kalkulahin ang ibig sabihin. Bago mo makalkula ang error para sa bawat pagsukat, dapat mong kalkulahin ang ibig sabihin ng buong hanay ng data. - Ang ibig sabihin ng isang hanay ng data ay ang kabuuan ng mga halagang hinati sa bilang ng mga halaga sa hanay. Ito ay maaaring kinatawan ng simbolo, na may variable
 Kalkulahin ang mga indibidwal na halaga ng error. Sa pangalawang haligi ng iyong talahanayan, dapat mong ipasok ang mga halaga ng error para sa bawat halaga ng data. Ang error ay ang pagkakaiba sa pagitan ng pagsukat at ng average.
Kalkulahin ang mga indibidwal na halaga ng error. Sa pangalawang haligi ng iyong talahanayan, dapat mong ipasok ang mga halaga ng error para sa bawat halaga ng data. Ang error ay ang pagkakaiba sa pagitan ng pagsukat at ng average. - Para sa ibinigay na hanay ng data, ibawas ang ibig sabihin, 98.87, mula sa bawat sinusukat na halaga at punan ang pangalawang haligi ng mga resulta. Ang sampung mga kalkulasyon na ito ay napupunta sa mga sumusunod:
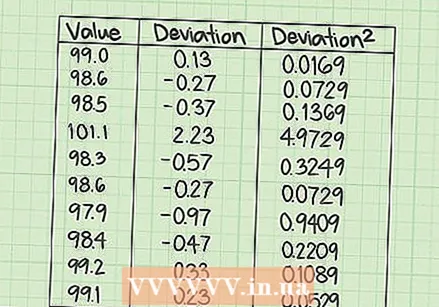 Kalkulahin ang SSE. Sa pangatlong haligi ng talahanayan, hanapin ang parisukat ng bawat isa sa mga nagresultang halaga sa gitnang haligi. Kinakatawan nito ang mga parisukat ng paglihis mula sa mean para sa bawat sinusukat na halaga ng data.
Kalkulahin ang SSE. Sa pangatlong haligi ng talahanayan, hanapin ang parisukat ng bawat isa sa mga nagresultang halaga sa gitnang haligi. Kinakatawan nito ang mga parisukat ng paglihis mula sa mean para sa bawat sinusukat na halaga ng data. - Para sa bawat halaga sa gitnang haligi, gumamit ng isang calculator upang makalkula ang parisukat. Itala ang mga resulta sa ikatlong haligi, tulad ng sumusunod:
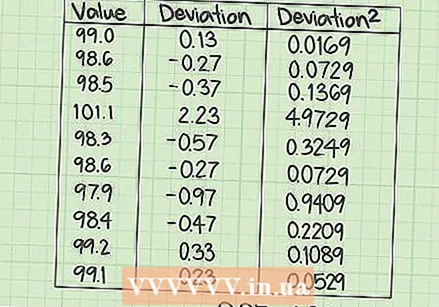 Idagdag ang mga parisukat ng mga error. Ang huling hakbang ay upang mahanap ang kabuuan ng mga halaga sa ikatlong haligi. Ang nais na resulta ay ang SSE, o ang kabuuan ng mga parisukat ng mga error.
Idagdag ang mga parisukat ng mga error. Ang huling hakbang ay upang mahanap ang kabuuan ng mga halaga sa ikatlong haligi. Ang nais na resulta ay ang SSE, o ang kabuuan ng mga parisukat ng mga error. - Para sa hanay ng data na ito, kinakalkula ang SSE sa pamamagitan ng pagdaragdag ng sampung mga halaga sa ikatlong haligi:
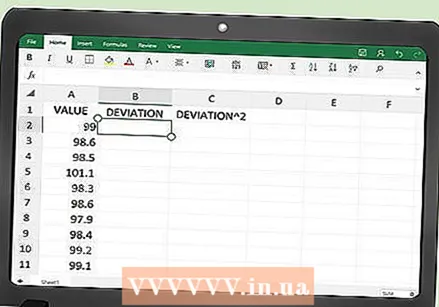
 Lagyan ng label ang mga haligi ng spreadsheet. Lumilikha ka ng isang talahanayan na may tatlong mga haligi sa Excel, na may parehong tatlong mga heading tulad ng nasa itaas.
Lagyan ng label ang mga haligi ng spreadsheet. Lumilikha ka ng isang talahanayan na may tatlong mga haligi sa Excel, na may parehong tatlong mga heading tulad ng nasa itaas. - Sa cell A1, i-type ang "Halaga" bilang heading.
- Sa kahon B1, i-type ang "Deviation" bilang heading.
- Sa kahon C1, i-type ang "Deviation square" bilang heading.
 Ipasok ang iyong mga detalye. Sa unang haligi kailangan mong ipasok ang mga halaga ng iyong mga sukat. Kung ang set ay maliit, madali mong mai-type ito sa pamamagitan ng kamay. Kung mayroon kang isang malaking hanay ng data, maaaring kailangan mong kopyahin at i-paste ang data sa haligi.
Ipasok ang iyong mga detalye. Sa unang haligi kailangan mong ipasok ang mga halaga ng iyong mga sukat. Kung ang set ay maliit, madali mong mai-type ito sa pamamagitan ng kamay. Kung mayroon kang isang malaking hanay ng data, maaaring kailangan mong kopyahin at i-paste ang data sa haligi. 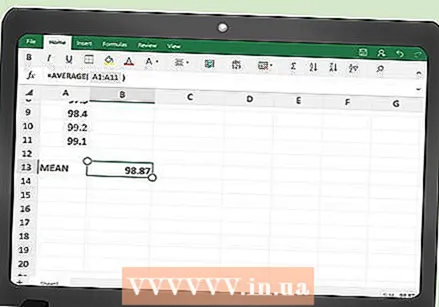 Tukuyin ang average ng mga puntos ng data. Ang Excel ay may isang function na kinakalkula ang average para sa iyo. Sa isang walang laman na cell sa ibaba ng iyong talahanayan ng data (hindi mahalaga kung aling cell ang pipiliin mo), ipasok ang sumusunod:
Tukuyin ang average ng mga puntos ng data. Ang Excel ay may isang function na kinakalkula ang average para sa iyo. Sa isang walang laman na cell sa ibaba ng iyong talahanayan ng data (hindi mahalaga kung aling cell ang pipiliin mo), ipasok ang sumusunod: - = Karaniwan (A2: ___)
- Huwag maglagay ng blangkong puwang. Punan ang puwang na iyon ng cell name ng iyong huling data point. Halimbawa, kung mayroon kang 100 mga puntos ng data, gagamitin mo ang pagpapaandar:
- = Karaniwan (A2: A101)
- Naglalaman ang pagpapaandar na ito ng data mula sa mga cell A2 hanggang A101, sapagkat ang tuktok na hilera ay naglalaman ng mga heading ng haligi.
- Kapag pinindot mo ang Enter o kapag nag-click ka sa isa pang cell sa talahanayan, ang bagong program na cell ay awtomatikong puno ng average ng iyong mga halaga ng data.
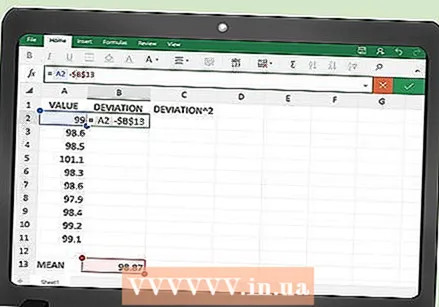 Ipasok ang pagpapaandar para sa mga sukat ng error. Sa unang walang laman na cell sa haligi na "Deviation", magpasok ng isang pagpapaandar upang makalkula ang pagkakaiba sa pagitan ng bawat data point at mean. Upang magawa ito, gamitin ang pangalan ng cell kung saan matatagpuan ang mean. Ipagpalagay natin na gumamit ka ng cell A104 sa ngayon.
Ipasok ang pagpapaandar para sa mga sukat ng error. Sa unang walang laman na cell sa haligi na "Deviation", magpasok ng isang pagpapaandar upang makalkula ang pagkakaiba sa pagitan ng bawat data point at mean. Upang magawa ito, gamitin ang pangalan ng cell kung saan matatagpuan ang mean. Ipagpalagay natin na gumamit ka ng cell A104 sa ngayon. - Ang pagpapaandar ng pagkalkula ng error na ipinasok mo sa cell B2 ay:
- = A2- $ A $ 104. Ang mga palatandaan ng dolyar ay kinakailangan upang matiyak na naka-lock mo ang kahon A104 para sa anumang pagkalkula.
- Ang pagpapaandar ng pagkalkula ng error na ipinasok mo sa cell B2 ay:
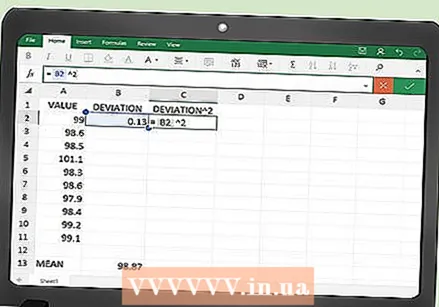 Ipasok ang pagpapaandar para sa mga parisukat na error. Sa ikatlong haligi maaari kang magturo sa Excel upang makalkula ang nais na parisukat.
Ipasok ang pagpapaandar para sa mga parisukat na error. Sa ikatlong haligi maaari kang magturo sa Excel upang makalkula ang nais na parisukat. - Sa cell C2, ipasok ang sumusunod na pagpapaandar:
- = B2 ^ 2
- Sa cell C2, ipasok ang sumusunod na pagpapaandar:
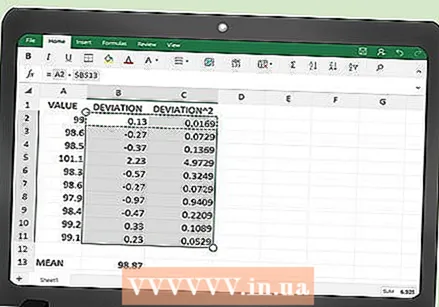 Kopyahin ang mga pagpapaandar upang punan ang buong talahanayan. Matapos ipasok ang mga pag-andar sa tuktok na cell ng bawat haligi, B2 at C2 ayon sa pagkakabanggit, kailangan mong punan ang buong talahanayan. Maaari mong mai-type muli ang pagpapaandar sa anumang linya ng talahanayan, ngunit ito ay magtatagal ng masyadong mahaba. Gamit ang iyong mouse, i-highlight ang mga cell B2 at C2 nang magkasama, at nang hindi inilalabas ang pindutan ng mouse, i-drag sa ilalim ng cell ng bawat haligi.
Kopyahin ang mga pagpapaandar upang punan ang buong talahanayan. Matapos ipasok ang mga pag-andar sa tuktok na cell ng bawat haligi, B2 at C2 ayon sa pagkakabanggit, kailangan mong punan ang buong talahanayan. Maaari mong mai-type muli ang pagpapaandar sa anumang linya ng talahanayan, ngunit ito ay magtatagal ng masyadong mahaba. Gamit ang iyong mouse, i-highlight ang mga cell B2 at C2 nang magkasama, at nang hindi inilalabas ang pindutan ng mouse, i-drag sa ilalim ng cell ng bawat haligi. - Ipagpalagay na mayroon kang 100 mga data point sa iyong talahanayan, i-drag ang iyong mouse sa mga cell B101 at C101.
- Kapag pinakawalan mo ang pindutan ng mouse, ang mga formula ay nakopya sa lahat ng mga cell ng talahanayan. Ang talahanayan ay dapat na awtomatikong puno ng mga kinakalkula na halaga.
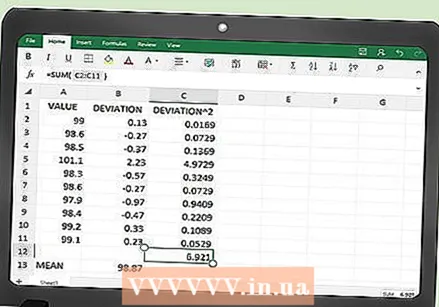 Hanapin ang SSE. Naglalaman ang haligi C ng iyong talahanayan ng lahat ng mga naka-square na mga halaga ng error. Ang huling hakbang ay hayaan ang Excel na kalkulahin ang kabuuan ng mga halagang ito.
Hanapin ang SSE. Naglalaman ang haligi C ng iyong talahanayan ng lahat ng mga naka-square na mga halaga ng error. Ang huling hakbang ay hayaan ang Excel na kalkulahin ang kabuuan ng mga halagang ito. - Sa isang cell sa ibaba ng talahanayan, marahil C102 sa halimbawang ito, ipasok ang sumusunod na pagpapaandar:
- = Kabuuan (C2: C101)
- Kung na-click mo ang Enter o pag-click ang layo sa isa pang cell ng talahanayan, makukuha mo ang halaga ng SSE ng iyong data.
- Sa isang cell sa ibaba ng talahanayan, marahil C102 sa halimbawang ito, ipasok ang sumusunod na pagpapaandar:
- Para sa bawat halaga sa gitnang haligi, gumamit ng isang calculator upang makalkula ang parisukat. Itala ang mga resulta sa ikatlong haligi, tulad ng sumusunod:
- Para sa ibinigay na hanay ng data, ibawas ang ibig sabihin, 98.87, mula sa bawat sinusukat na halaga at punan ang pangalawang haligi ng mga resulta. Ang sampung mga kalkulasyon na ito ay napupunta sa mga sumusunod:
- Ang ibig sabihin ng isang hanay ng data ay ang kabuuan ng mga halagang hinati sa bilang ng mga halaga sa hanay. Ito ay maaaring kinatawan ng simbolo, na may variable
Paraan 3 ng 3: Iugnay ang SSE sa iba pang mga istatistika
 Kalkulahin ang paglihis mula sa SSE. Ang paghahanap ng SSE para sa isang dataset sa pangkalahatan ay isang bloke ng gusali para sa paghahanap ng iba pang, mas kapaki-pakinabang, na mga halaga. Ang una sa mga ito ay pagkakaiba-iba. Ang pagkakaiba-iba ay isang sukatan kung magkano ang sinusukat na data ay lumihis mula sa mean. Ito talaga ang ibig sabihin ng mga parisukat na pagkakaiba mula sa ibig sabihin.
Kalkulahin ang paglihis mula sa SSE. Ang paghahanap ng SSE para sa isang dataset sa pangkalahatan ay isang bloke ng gusali para sa paghahanap ng iba pang, mas kapaki-pakinabang, na mga halaga. Ang una sa mga ito ay pagkakaiba-iba. Ang pagkakaiba-iba ay isang sukatan kung magkano ang sinusukat na data ay lumihis mula sa mean. Ito talaga ang ibig sabihin ng mga parisukat na pagkakaiba mula sa ibig sabihin. - Dahil ang SSE ay kabuuan ng mga parisukat na error, mahahanap mo ang ibig sabihin (iyon ang pagkakaiba-iba) sa pamamagitan lamang ng paghahati sa bilang ng mga halaga. Gayunpaman, kung kinakalkula mo ang pagkakaiba-iba ng isang sample na serye, sa halip na isang buong populasyon, hinati mo ang pagkakaiba-iba ng (n-1) sa halip na ng n. Kaya:
- Pagkakaiba = SSE / n, kung kinakalkula mo ang pagkakaiba-iba ng isang buong populasyon.
- Pagkakaiba = SSE / (n-1), kapag kinakalkula ang pagkakaiba-iba ng isang sample ng data.
- Para sa problema sa sampling ng temperatura ng mga pasyente, maaari nating ipalagay na ang 10 mga pasyente ay isang sample lamang. Samakatuwid, ang pagkakaiba-iba ay kinakalkula bilang mga sumusunod:
 Kalkulahin ang karaniwang paglihis ng SSE. Ang karaniwang paglihis ay isang karaniwang ginagamit na halaga na nagpapahiwatig kung gaano kalayo ang mga halaga ng isang hanay ng data na lumihis mula sa ibig sabihin. Ang karaniwang paglihis ay ang parisukat na ugat ng pagkakaiba-iba. Tandaan na ang pagkakaiba ay ang ibig sabihin ng mga parisukat na mga sukat ng error.
Kalkulahin ang karaniwang paglihis ng SSE. Ang karaniwang paglihis ay isang karaniwang ginagamit na halaga na nagpapahiwatig kung gaano kalayo ang mga halaga ng isang hanay ng data na lumihis mula sa ibig sabihin. Ang karaniwang paglihis ay ang parisukat na ugat ng pagkakaiba-iba. Tandaan na ang pagkakaiba ay ang ibig sabihin ng mga parisukat na mga sukat ng error. - Samakatuwid, pagkatapos kalkulahin ang SSE, mahahanap mo ang karaniwang paglihis tulad nito:
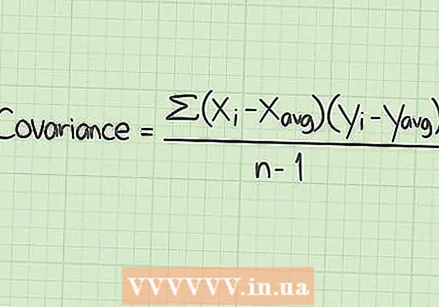 Gumamit ng SSE upang matukoy ang covariance. Ang artikulong ito ay nakatuon sa mga dataset na sumusukat lamang sa isang solong halaga nang paisa-isa. Gayunpaman, sa maraming mga pag-aaral maaari kang maghambing ng dalawang magkakahiwalay na halaga. Halimbawa, nais mong malaman kung paano nauugnay ang dalawang halagang iyon sa bawat isa, hindi lamang sa ibig sabihin ng hanay ng data. Ang halagang ito ay ang covariance.
Gumamit ng SSE upang matukoy ang covariance. Ang artikulong ito ay nakatuon sa mga dataset na sumusukat lamang sa isang solong halaga nang paisa-isa. Gayunpaman, sa maraming mga pag-aaral maaari kang maghambing ng dalawang magkakahiwalay na halaga. Halimbawa, nais mong malaman kung paano nauugnay ang dalawang halagang iyon sa bawat isa, hindi lamang sa ibig sabihin ng hanay ng data. Ang halagang ito ay ang covariance. - Ang mga kalkulasyon para sa covariance ay masyadong detalyado upang mailarawan dito, maliban na tandaan na gagamitin mo ang SSE para sa bawat uri ng data at pagkatapos ihambing ito. Para sa isang mas detalyadong paglalarawan ng covariance at mga kalkulasyon na kasangkot, maaari kang makahanap ng mga artikulo sa paksang ito sa wikiHow.
- Bilang isang halimbawa ng paggamit ng covariance, maihahambing mo ang edad ng mga pasyente sa isang medikal na pag-aaral na may bisa ng gamot sa pagbaba ng temperatura ng lagnat. Pagkatapos ay mayroon kang isang hanay ng data ng mga edad at isang pangalawang hanay ng data ng mga temperatura. Mahahanap mo ang SSE para sa bawat hanay ng data, at mula roon ang pagkakaiba-iba, karaniwang mga paglihis at covariance.
- Samakatuwid, pagkatapos kalkulahin ang SSE, mahahanap mo ang karaniwang paglihis tulad nito:
- Dahil ang SSE ay kabuuan ng mga parisukat na error, mahahanap mo ang ibig sabihin (iyon ang pagkakaiba-iba) sa pamamagitan lamang ng paghahati sa bilang ng mga halaga. Gayunpaman, kung kinakalkula mo ang pagkakaiba-iba ng isang sample na serye, sa halip na isang buong populasyon, hinati mo ang pagkakaiba-iba ng (n-1) sa halip na ng n. Kaya:



